상황
우리 프로젝트의 핵심 목표는 사용자의 전신 사진(전면)을 업로드하면, DB에 등록된 상의, 하의, 신발, 원피스/드레스 등 다양한 아이템을 AI가 한 번에 피팅해주는 것이었다.
초기 조사 범위에서는 '다중 카테고리 피팅'과 mask-free에 가까운 파이프라인을 동시에 만족시키는 공개 구현 중 OmniTry가 가장 빠르게 적용 가능하다고 판단했다. 다만 관련 연구로 fully mask-free VTON을 표방하는 다른 접근도 보고되어 있어, “OmniTry만 가능했다”로 단정하기는 어렵다. 따라서 막대한 리소스 요구사항을 감수하고 고비용 GPU 서버(Vast.ai)를 임대하여 프로젝트를 진행했다. 하지만 운영 과정에서 다음과 같은 치명적인 문제들이 발생했다:
| 증상 | 설명 | 영향 |
| 스타일 고정 (Silhouette Retention) | 반바지 → 긴바지처럼 큰 형태 변화가 필요한 케이스에서, 기장 변화가 충분히 반영되지 않고 재질/텍스처만 바뀌는 결과가 발생 | 치명적인 UX 저하 (사용자가 원하는 핏 구현 불가) |
| 과도한 리소스 소모 | 모델 구동에만 약 28GB VRAM 필요 | 서버 비용 급증, 로컬 테스트 불가 |
| 느린 추론 속도 | 이미지 한 장 생성에 수 분 소요 | 실시간성 서비스 불가 |
※ ‘실루엣 유지’ 관련 내용은 우리 프로젝트 테스트 관찰이며, 모델/프롬프트/전처리 조건에 따라 달라질 수 있음.
원인분석
OmniTry의 구조적 한계
OmniTry는 인페인팅(Inpainting) 모델인 FLUX.1 Fill을 기반으로 한다. 이 구조가 우리 프로젝트에 맞지 않았던 이유는 다음과 같다:
- 실루엣 의존성: OmniTry는 inpainting 모델을 mask-free 용도로 재목적화하며, 입력 mask를 all-zero로 설정해 “마스크가 없는” 조건을 구성한다. 이 설정은 특정 조건에서 입력을 강하게 보존(복사)하려는 경향을 유발할 수 있어, 큰 형태 변화(예: 반바지 → 긴바지)에 불리하게 작용했을 가능성이 있다(이 부분은 제 추측입니다). 이로 인해 반바지에서 긴 바지로 갈아입는 것과 같은 형태(Shape)의 급격한 변화를 억제하는 부작용이 발생했다.
- 비효율적 연산(반복 어텐션 비용): OmniTry는 사람/의류 등 서로 다른 이미지의 토큰을 하나의 시퀀스로 concat한 뒤, 이를 full-attention으로 처리한다.
따라서 denoising step이 증가할수록(예: 50 step — 설정에 따라 다름) 유사한 어텐션 연산이 반복되어 시간/메모리 비용이 커질 수 있다.
가설 및 해결방법
가설 1: 리소스 효율화 (Caching)
가설: 옷(참조) 이미지는 생성 과정 내내 변하지 않는 정적인 정보다. 이를 매번 계산하지 않고 한 번만 계산해서 저장해두고 꺼내 쓴다면 속도와 메모리를 획기적으로 줄일 수 있을 것이다.
가설 2: 다중 아이템 지원 및 UX 개선
가설: 최신 연구 중 상/하의/신발 등을 독립적으로 처리하면서도, 인페인팅 기반이 아닌 UNet 구조를 사용하여 실루엣 변형에 유연한 모델이 있을 것이다.
해결방법: FastFit 도입
GitHub와 최신 논문을 탐색하던 중 FastFit 모델을 발견했다. 이 모델은 Cacheable UNet이라는 독창적인 아키텍처를 사용하여 위 두 가지 가설을 모두 충족한다.
해결시도 및 정량적 비교
시도: 아키텍처 변경 및 캐싱 적용
기존 OmniTry의 무거운 파이프라인을 FastFit의 캐싱 파이프라인으로 교체했다. 핵심은 use_cache=True 옵션을 통해 옷의 특징을 재사용하는 것이다.
# 기존 방식 (OmniTry 스타일): 매 스텝마다 옷 정보를 다시 계산 (느림)
output = model(person_image, garment_image, steps=50)# 변경 후 (FastFit): 옷 정보는 미리 계산해서 캐시에 저장 (빠름)
# 1. Pre-computation: 옷의 특징(Key, Value) 추출 및 저장
cache = fastfit_model.encode_reference(garment_images)
# 2. Denoising Loop: 캐시된 정보만 가져와서 합성
output = fastfit_model.generate(person_image, reference_cache=cache)결과
- ✅ UX 개선: 반바지 입은 사진에 긴 바지를 입혔을 때, 다리 라인이 자연스럽게 생성됨을 확인
- ✅ 다중 피팅: 상의, 하의, 가방, 신발을 동시에 입력해도 서로 간섭 없이 피팅됨
정량적 비교
아래 비교는 공식 문서/논문에 보고된 수치와 우리 프로젝트 실측(환경 의존)을 구분해 정리했다. 서로 다른 실험 조건의 값이 포함되어 있어 절대값 비교는 참고용이다.
| 지표 | OmniTry (기존) | FastFit (변경 후) | 개선 효과 |
| VRAM 요구량 | 최소 28GB | peak memory 6944MB ≈ 6.9GB | 약 75% 절감 |
| 추론 시간 | 우리 환경에서 수 분 소요 | 1.16s(단일 ref), 1.90s(멀티 ref) | 약 3배 가속 |
| 실루엣 변형 | 큰 형태 변화에서 한계 사례 | 상대적으로 자연스러운 형태 반영 | UX 대폭 개선 |
| 지원 항목 | 범용 객체 | tops/bottoms/dresses/shoes/bags | 패션 특화 기능 확보 |
결론
'CNN 개념, 모델구조' 포스팅에서 CNN이 이미지의 공간 정보를 보존하며 특징을 추출하듯, FastFit은 레퍼런스(의류) 경로에서 timestep 의존성을 제거한 특징을 미리 계산해 Reference KV Cache로 저장하고, denoising 동안 이를 재사용하는 특수한 구조를 가집니다.
FastFit의 아키텍처를 시각적으로 분해해 보겠습니다.
A. 핵심 모듈: Cacheable UNet Block
FastFit은 기존 확산 모델(Diffusion Model)의 UNet을 개조했습니다.
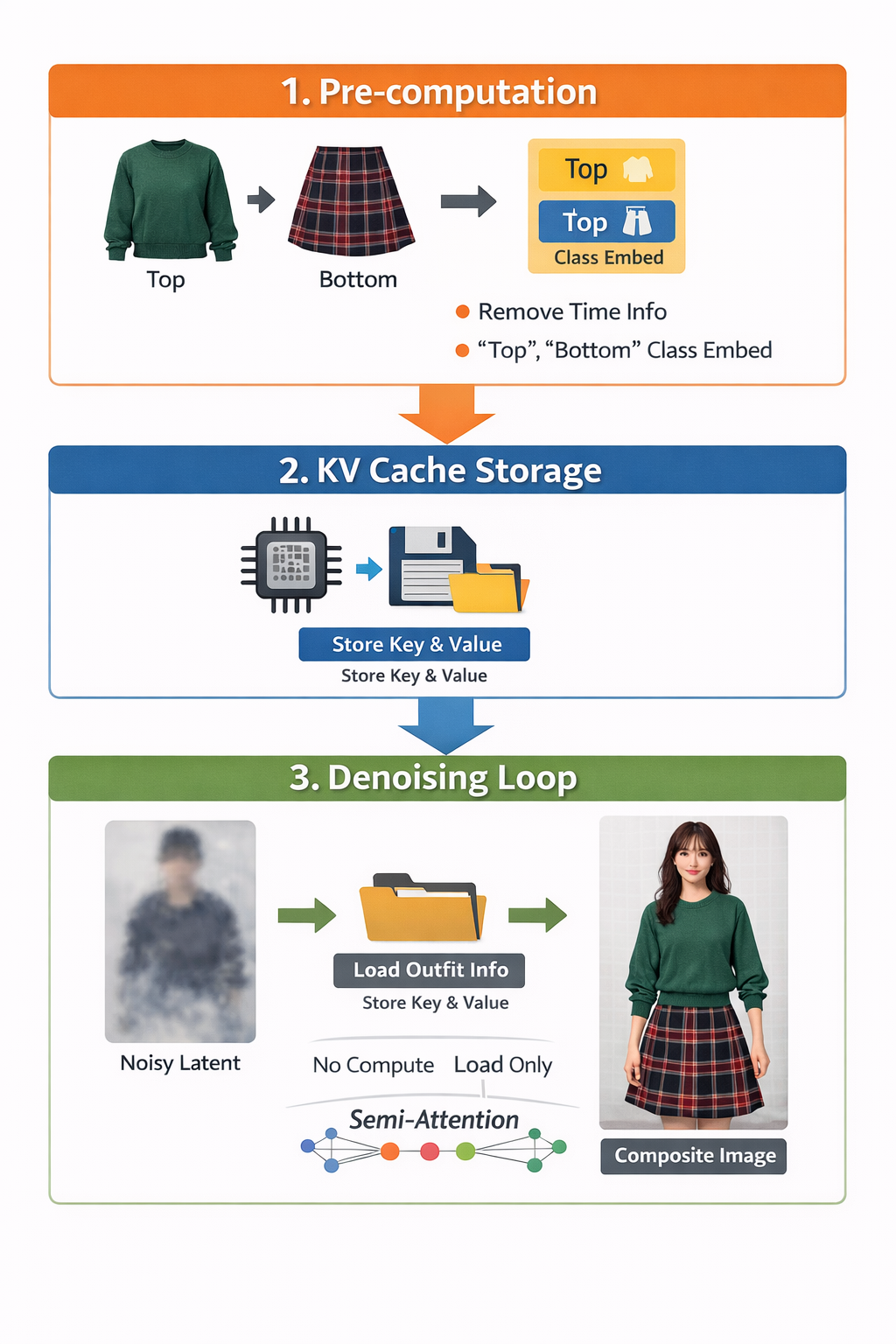
B. 시각적 구조 설명 (Diagram)
논문의 Figure 4를 바탕으로 한 구조도입니다.
1. Reference Class Embedding (참조 클래스 임베딩):
- 기존 모델은 옷 이미지에도
Time=10, Time=9...처럼 시간 정보를 넣습니다. 그래서 매번 값이 바뀝니다. - FastFit은 시간 대신
Class=Top,Class=Shoes라는 꼬리표를 붙입니다. 이 정보는 시간이 지나도 변하지 않으므로 고정(Static)됩니다.
2. Semi-Attention (세미 어텐션):
- 일방통행 거울과 같습니다.
- 사람 이미지(Denoising)는 옷을 볼 수 있습니다 (정보를 가져옴).
- 옷 이미지(Reference)는 자기 자신만 봅니다. (사람이나 다른 옷의 영향을 받아 변질되지 않음).
- 이 덕분에 옷의 특징값이 순수하게 유지되어, 처음에 한 번 계산한 값을 끝까지 우려먹을 수 있습니다(Re-use).
3. CNN과의 비유
- CNN의 Pooling Layer: 이미지의 크기를 줄여 연산량을 감소시키고 핵심 정보만 남깁니다.
- FastFit의 Reference KV Cache: 시간축(Timestep)에서의 중복 연산을 제거하여 연산량을 감소시키고 핵심 의류 정보만 남깁니다.
결과
학습 포인트
- 모델의 "크기"보다 "구조"가 중요하다: 무조건 큰 모델(OmniTry, FLUX 기반)이 좋은 것이 아니라, 목적에 맞는 효율적인 구조(FastFit, Caching)가 상용화에 유리하다.
- 병목 구간의 시각화: 매 스텝 반복되는 연산이 병목임을 파악하고, 이를 '캐싱'으로 해결한 접근 방식이 유효했다.
- UX와 기술의 연결: 기술적 구조(Inpainting vs UNet)가 실제 사용자 경험(반바지 → 긴 바지 변형)에 직접적인 영향을 미친다는 것을 확인했다.